

Pod issue
กรณีที่ทำการ run pipeline เรียบร้อยแต่มีปัญหากับ pod มีสถานะ pending หรือขึ้นแจ้งเตือน ในหัวข้อนี้จะบอกวิธีการตรวจสอบ pod ที่มีปัญหา และวิธีการแก้ไข
วิธีดู pod descripe
กรณีที่ pod มีปัญหาสามารถใช้คำสั่งนี้เพื่อดูรายละเอียด และปัญหาที่ pod ไม่ขึ้นได้เช่นกัน
kubectl -n <namespace> describe pod <podname>กรณีที่มีปัญหาจะบอกว่า state อะไรติดปัญหาอะไร, กำลังทำ event อะไรค้างอยู่ หรือมีรายการ warning เพิ่มขึ้นมาดังตัวอย่าง
ใช้คำสั่งเพื่อดู pod
kubectl -n consultant-hybridcloud-ecommerce-dev describe pod consultant-hybridcloud-ecommerce-api-guide-develop-5cdd7c6l8n68จะได้รายละเอียดของ pod ดังตัวอย่าง
Name: consultant-hybridcloud-ecommerce-api-guide-develop-5cdd7c6l8n68
Namespace: consultant-hybridcloud-ecommerce-dev
Priority: 0
Service Account: default
Node: gke-opstella-dev-clu-spot-6vcpu-16mem-0fb2c850-d9sq/10.56.0.199
Start Time: Wed, 03 Jul 2024 08:28:21 +0700
Labels: app.kubernetes.io/instance=consultant-hybridcloud-ecommerce-api-guide-develop
app.kubernetes.io/name=xxx
pod-template-hash=5cdd7c66d
Annotations: checksum/config: e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855
Status: Pending
IP: 10.22.3.97
IPs:
IP: 10.22.3.97
Controlled By: ReplicaSet/consultant-hybridcloud-ecommerce-api-guide-develop-5cdd7c66d
Containers:
consultant-hybridcloud-ecommerce-api-guide-develop:
Container ID:
Image: nginx:xxx
Image ID:
Port: 3000/TCP
Host Port: 0/TCP
State: Waiting
Reason: ImagePullBackOff
Ready: False
Restart Count: 0
Limits:
cpu: 500m
memory: 500Mi
Requests:
cpu: 10m
memory: 10Mi
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-96tcs (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
kube-api-access-96tcs:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Pulling 22m (x34 over 172m) kubelet Pulling image "nginx:xxx"
Normal BackOff 2m36s (x737 over 172m) kubelet Back-off pulling image "nginx:xxx"จากตัวอย่างหลังดูสถานะของ pod จะขึ้นแจ้งว่า state ของ container คือ waiting และ มี reason บอกสาเหตุว่า ImagePullBackOff ส่วนล่างสุดจะมี event บอกการทำงานที่ติดปัญหา เป็นต้น
หรือสามารถดูปัญหาผ่าน ArgoCD ได้เช่นกัน โดยการเปิด ArgoCD จากใน Component นั้น ดังขั้นตอนต่อไปนี้
- หลังเปิด argoCD และ login เข้ามาจะเจอหน้า Application Details ไปดู deatil ของ pod ที่มีปัญหา
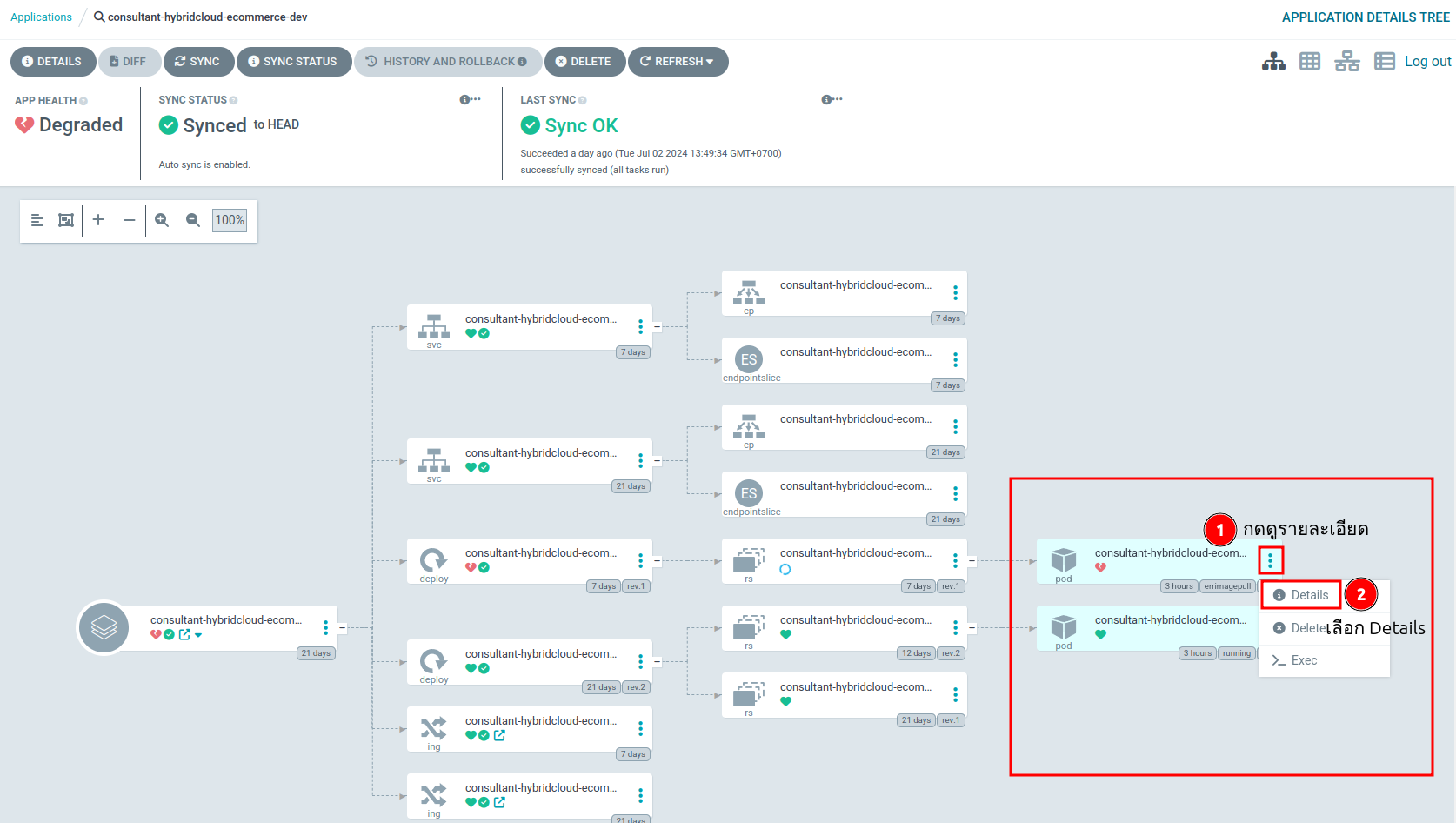
- รายละเอียดขณะนั้นของ pod
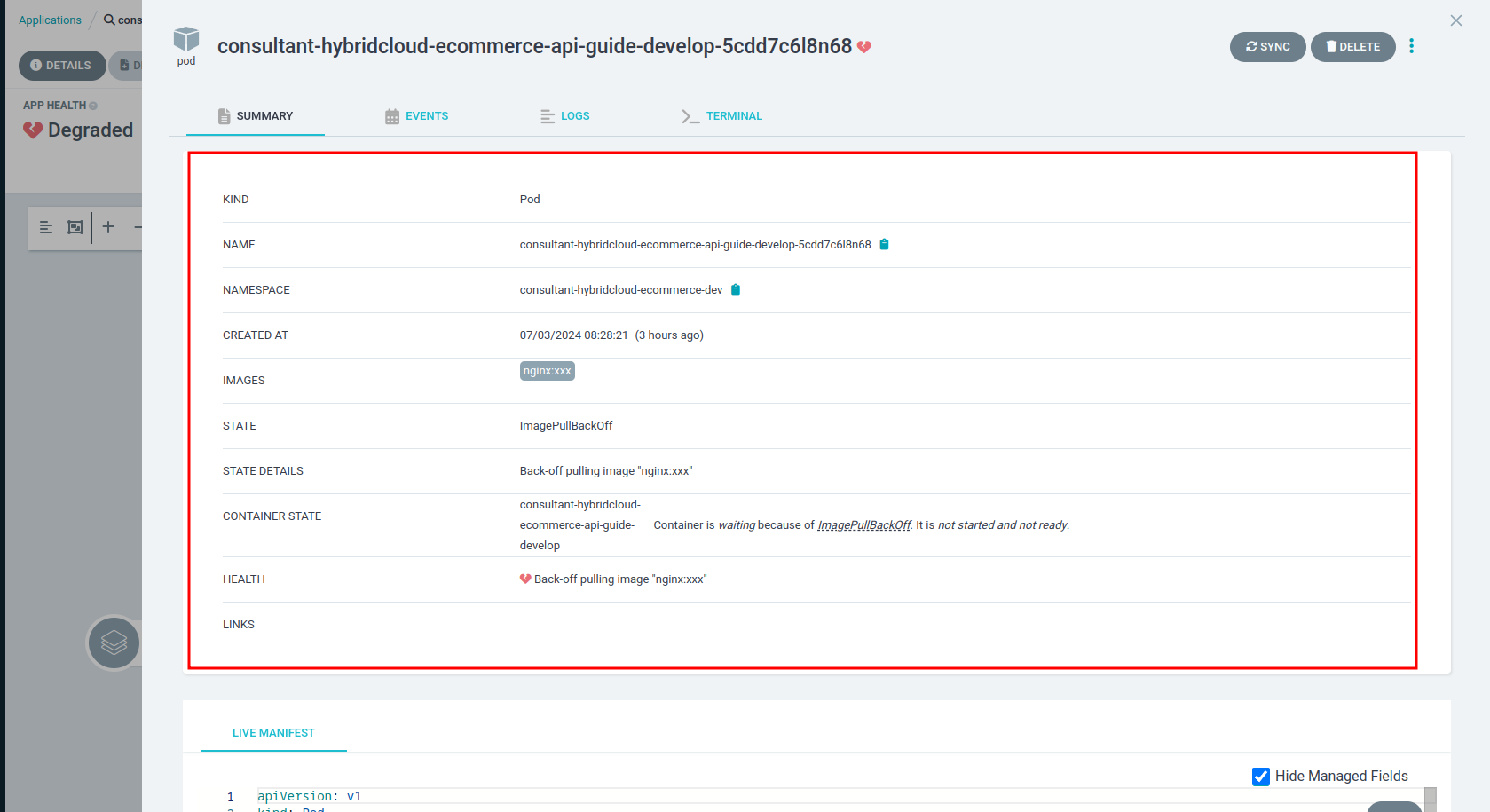
ในหัวข้อตอไปจะดูว่า pod จะมีปัญหาในแต่ละขั้นตอนอย่างไรขณะเปลี่ยนสถานะจาก pending เป็น running
สถานะการทำงานของ pod
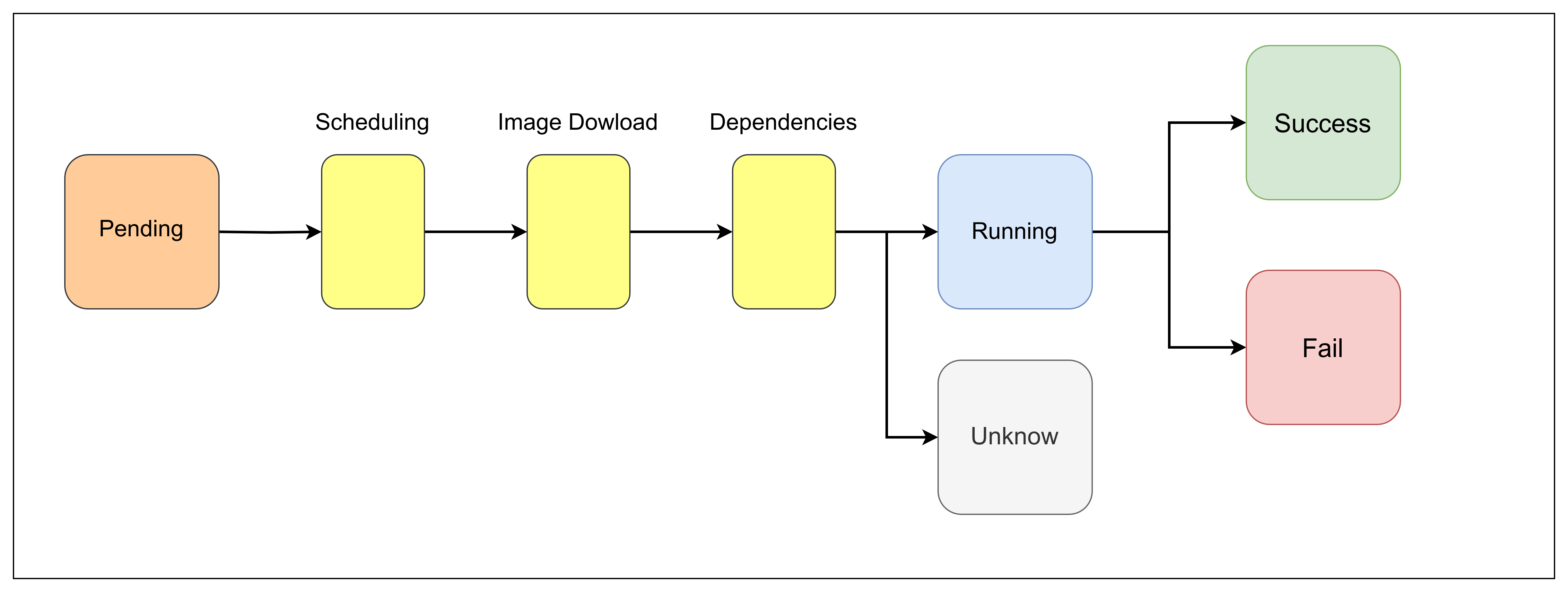
เมื่อ pod ถูกสร้างจะมีสถานะ pending ในระหว่างที่จะขึ้นสถานะ running จะมีการทำตามลำดับ ดังนี้
- Schecdulling
- Image Dowload
- Dependencies
หลังจากที่ Running แล้วถ้าการทำงานภายใน pod ไม่มีปัญหาก็ทำงานปกติ แต่มีปัญหาอาจจะทำให้ pod down และต้องทำการ re-pod ซึ่งในหัวข้อนี้จะโฟกัสในวิธีแก้ปัญหาเมื่อ pod มีสถานะ pending ขณะที่กำลังเปลี่ยนเป็น running
Schedulling
กรณีที่มีการขึ้น pod ขึ้นมาจะมีการขึ้น pod บน node อาจเจอปัญหา resource ไม่พออาจเกิดได้ทั้งจาก
- ต้องค่า request,limit ของ pod มากเกินไป
- ตั้ง replicaset มากเกินไป
ปัญหาส่วนใหญ่จึงมากเกิดจาก resource ไม่พอ
Resource ไม่พอ
วิธีตรวจสอบ
ใช้คำสั่ง
kubectl -n <namespace> describe pod <podname>หรือตรวจสอบใน ArgoCD พบแจ้งเตือน
0/4 nodes are available: 2 Insufficient cpu, 2 Insufficient memory. preemption: 0/4 nodes are available: 4 No preemption victims found for incoming pod.วิธีแก้
แก้ไฟล์ helm values ของ pod นั้นในหน้า component detail แก้ค่า requests และ limits ใน resources ให้ลดลงไม่เกิน resources ของ Service ดังรูป
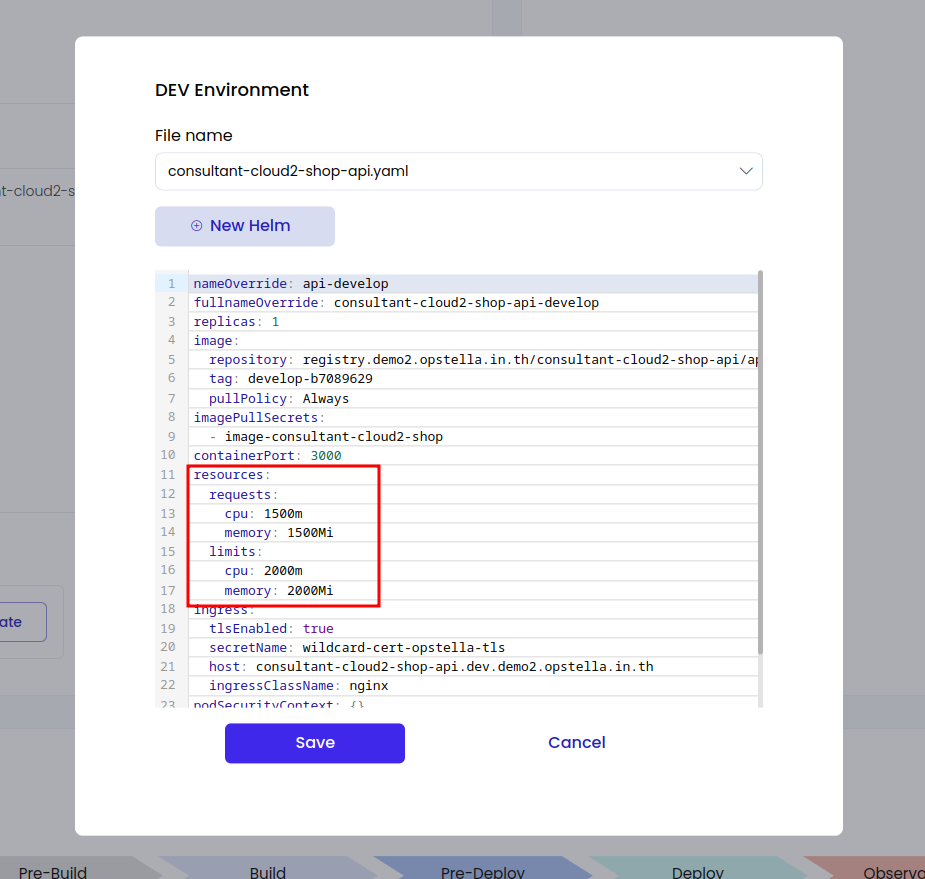
หรือเพิ่ม resources ของ Service โดยไปที่ หน้า Edit Service ดังรูป
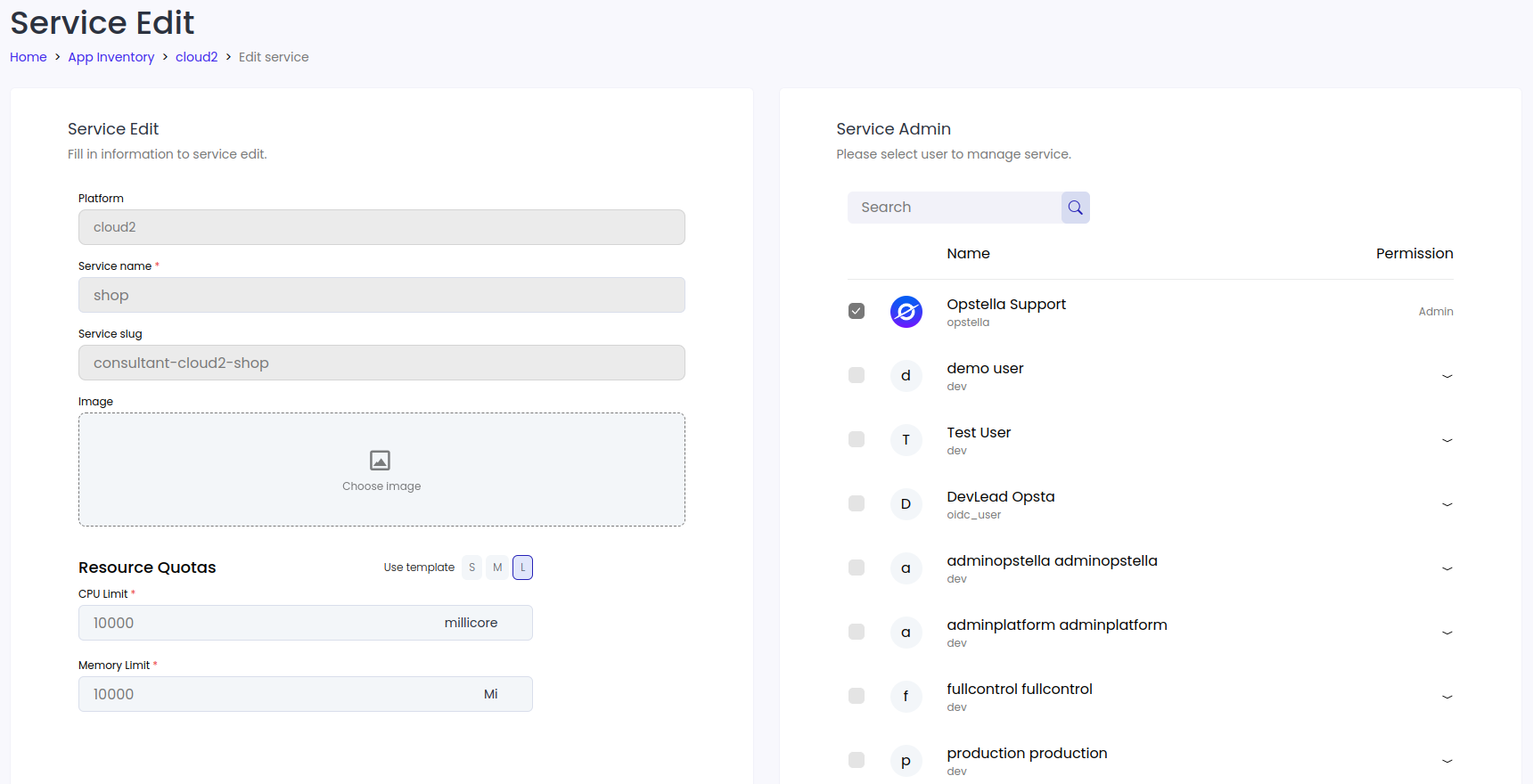
หากยังติดปัญหาให้ทำการแก้ resources ของ Platform ด้วย จนได้ขนาด resource ที่ pod ต้องการ
Image Dowload
ในขั้นตอนนี้ pod จะทำการ dowload image ตามที่กำหนดไว้ซึ่งหากติดปัญหาจะทำไม่สามารถเปลี่ยนเป็นสถานะ running ได้ ปัญหาการ dowload มักเกินจากสาเหตุ ดังต่อไปนี้
Pull image ไม่ได้จากข้อมูลผิด
ข้อมูลที่สามารถผิดแล้วไม่สามารถ dowload image ได้ ประกอบ
- ชื่อ image ผิด
- ชื่อ tag ของ image ผิด
- repository ที่เก็บ image ผิด
- ไม่สามารถ authentication กับ Repository ที่เก็บ image ได้
ซึ่งอย่างใดอย่างนึงก็สามารถทำให้เกิดปัญหาได้
วิธีตรวจสอบ
ใช้คำสั่ง
kubectl -n <namespace> describe pod <podname>หรือตรวจสอบใน ArgoCD พบแจ้งเตือน
Error: ErrImagePullหรือ
Error: ImagePullBackOffวิธีการแก้ไข
ตรวจสอบแก้ไขชื่อ Image, Tag หรือ Repository ให้ถูกต้อง แล้วทำการลบ pod เดิม และรอขึ้น pod ใหม่
Dependencies
เกิดจากปัญหาจาก Dependency ที่ pod ต้องใช้ หรือกำหนดให้เรียกใช้ เช่น Service, ConfigMap, Secret, PersistentVolume, Pod อื่นๆ
วิธีการตรวจสอบ
ใช้คำสั่ง
kubectl -n <namespace> describe pod <podname>หรือตรวจสอบใน ArgoCD พบแจ้งเตือน
MountVolume.SetUp failed for volume <ชื่อ resource> : <ชนิด resource> <ชื่อ resource> not foundวิธีการแก้ไข
สร้าง resource ที่หายไปใน namespace เดียวกัน แล้วทำการ re-pod