

Opensearch Index
Opensearch คือ ชุดการค้นหาและการวิเคราะห์แบบกระจายศูนย์ ได้รับสิทธิ์การใช้งาน Apache 2.0 ซึ่งนำไปใช้ได้หลากหลายรูปแบบ เช่น การติดตามตรวจสอบแอปพลิเคชันแบบเรียลไทม์ การวิเคราะห์ข้อมูล log ฯลฯ
Intro Opensearch
Document
Document คือ รูปแบบข้อมูลในรูปแบบฐานข้อมูลที่แปลงมาเป็นแบบ JSON ใน Opensearch โดยประเภทข้อมูลต่างๆ จะเหมือนกับของฐานข้อมูล (Number, String, Date) เช่น
| id | firstname | lastname | age |
|---|---|---|---|
| 1 | John | Doe | 25 |
| 2 | Jane | Doe | 25 |
{
id: 1,
firstname: 'John',
lastname: 'Doe',
age: 25
},
{
id: 2,
firstname: 'Jane',
lastname: 'Doe',
age: 25
}index
index คือ การรวมสิ่งที่เหมือนกันของ document โดยเฉพาะ (คล้าย index ของฐานข้อมูล) โดยจะเก็บข้อมูลตาม index เช่น สร้าง index ของ age เพื่อเก็บอายุของผู้ใช้, firstname เพื่อเก็บชื่อของผู้ใช้ และ lastname เพื่อเก็บนามสกุลของผู้ใช้ เป็นต้น
Cluster and Node
node คือ เสมือนคอมพิวเตอร์หนึ่งเครื่องใน cluster
cluster คือ กลุ่มของ node
Opensearch ออกแบบให้เป็น search engine แบบกระจายศูนย์จึงสามารถทำงานบนหลาย node ที่อยู่บน cluster เดียวกันได้
shards
shards คือ การแบ่ง index ในหลาย node เพราะ การกระจาย index ที่มีขนาดใหญ่ในหลาย node ช่วยให้สามารถค้นหาข้อมูลได้เร็วขึ้น ดังรูป
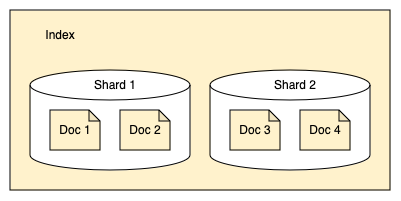
โดยในแต่ละ node ที่เก็บ index เดียวกันแต่อาจจะเเบ่งเป็นคนละ shard ดังรูป
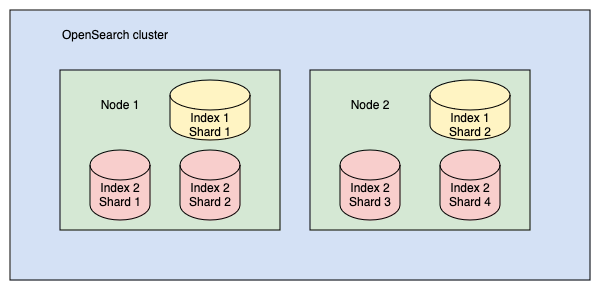
ในรูปตัวอย่างจะมี 2 index ใน 2 node โดย index 1 แบ่งเป็น 2 shards และ index 2 แบ่งเป็น 4 shards การแบ่งเป็น shards เหมาะสำหรับ index ที่มีขนาดใหญ่มาก เช่น 500 GB ใน 1 node
การแบ่งออกเป็นหลาย shards จะทำงานได้ดีกว่า เช่น แบ่งเป็น 10 shards ใน 10 node อย่างไรก็ตาม ในทุก shards มีการใช้งาน Lucene full index หากมีการแบ่ง shards ที่มากเกินไปจะทำให้เปลือง CPU และ Memory เกินความเจำเป็น จึงควรพิจารณาตามความเหมาะสม
Primary and replica shards
ในระบบ OpenSearch (และ Elasticsearch) การจัดการข้อมูลและการค้นหาข้อมูลมีการใช้ shards เพื่อกระจายโหลดและเพิ่มประสิทธิภาพในการค้นหา Shards ถูกแบ่งออกเป็นสองประเภทหลักคือ Primary Shards และ Replica Shards
Primary Shards
คือ ส่วนหลักของ index ที่มีข้อมูลดั้งเดิม และเป็นแหล่งที่มาของข้อมูลที่ถูกใช้ในการกระจายข้อมูลไปยัง Replica Shards
Replica Shards
คือ สำเนาของ Primary Shards มีหน้าที่ในการสำรองข้อมูลเพื่อเพิ่มความทนทานของระบบ (fault tolerance) และช่วยกระจายโหลดในการค้นหา (search load)
การทำงานของ Primary และ Replica Shards
เมื่อมีการเก็บข้อมูลเพิ่มเข้ามาภายใน index จะเพิ่มเข้ามาใน primary จากนั้นจึงค่อยทำการ คัดลอกข้อมูลไปยัง Replica ดังตาราง
| Node | Shards |
|---|---|
| Node 1 | Primary shards 1, Replica shards 2 |
| Node 2 | Primary shards 2, Replica shards 3 |
| Node 3 | Primary shards 3, Replica shards 1 |
จากตารางจะเห็นว่ามีการเก็บ Primary shards และ Replica Shards แยกคนละ Node เพิ่มมีการเพิ่มใน Primary แต่ละ Replica จะทำสำเนาข้อมูลที่เพิ่มมา และในการค้นหาจะทำการค้นหาในทั้ง Primary และ Replica ซึ่งจะลด load ในแต่ละ node ได้ จึงเป็นการเพิ่มประสิทธิภาพในการค้นหา นอกจากนี้การกระจายข้อมูลในหลาย Node ยังสามารถลดความเสี่ยงในกรณีที่ Node ล่มจะยังเข้าถึงข้อมูลในอีก Node ได้อยู่
อ่านเพิ่มเติมได้ที่ Introduction to OpenSearch
การใช้งาน Opensearch เบื้องต้น
Fluentbit
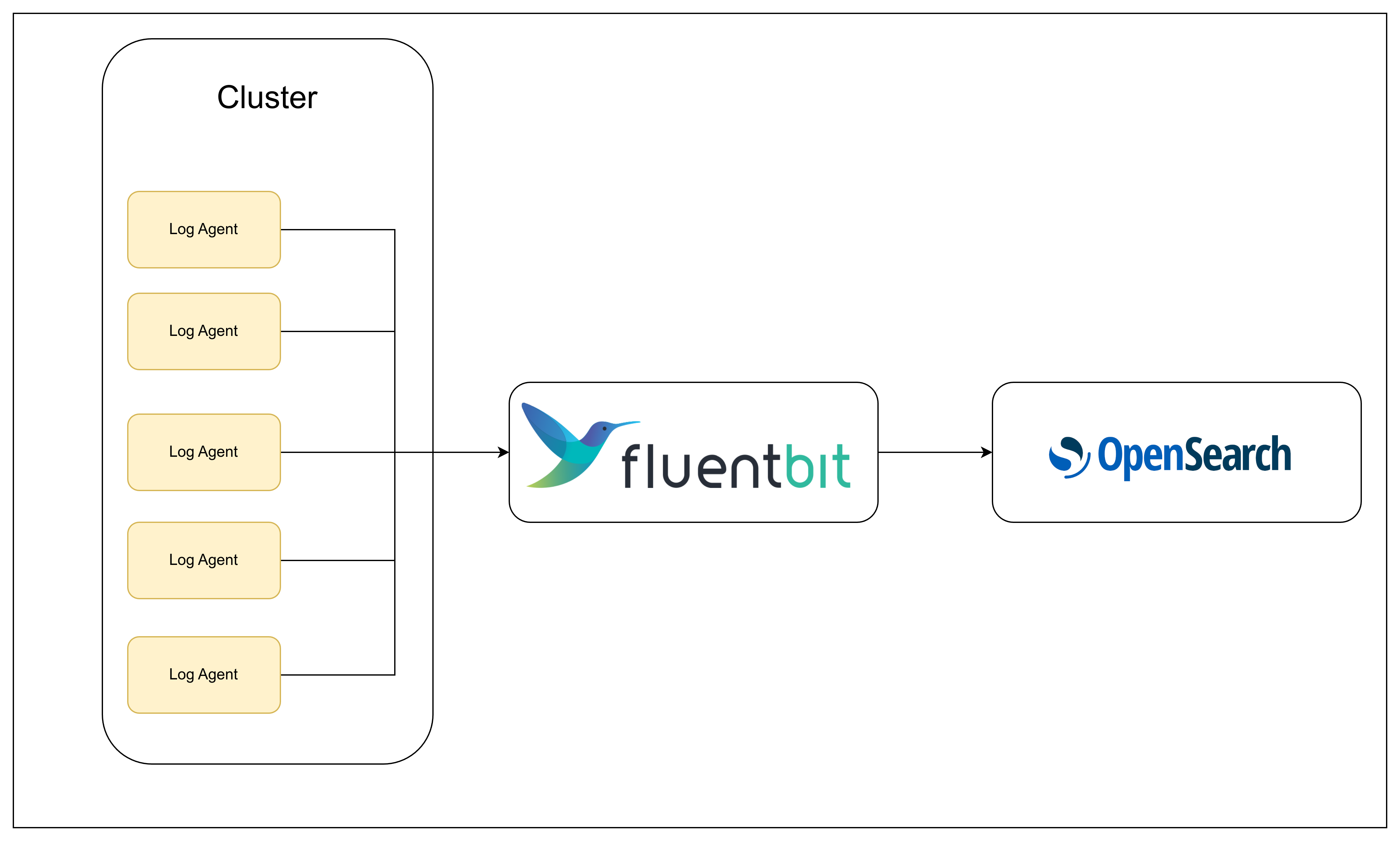
ใน Opstella จะมีการสร้าง Pod Log Agent ตาม namesapce ของ service ขึ้นมาเพื่อดึง Log ส่งไปยัง Fluentbit แล้ว Fluentbit จะส่งต่อไปยัง Opensearch อีกที ดังรูป
การสร้าง index pattern
index pattern คือ pattern สำหรับการเรียกหลาย index ที่มีชื่อคล้ายกัน เช่น app-* คือ ทุก index ที่ชื่อขึ้นต้นด้วย "app-" การสร้าง index ภายใน opensearch มีดังนี้
- เปิด devops tools opensearch
- ไปที่ บาร์ ด้านซ้ายมือเลือนลงมาด้านล่างสุดเลือก stack management
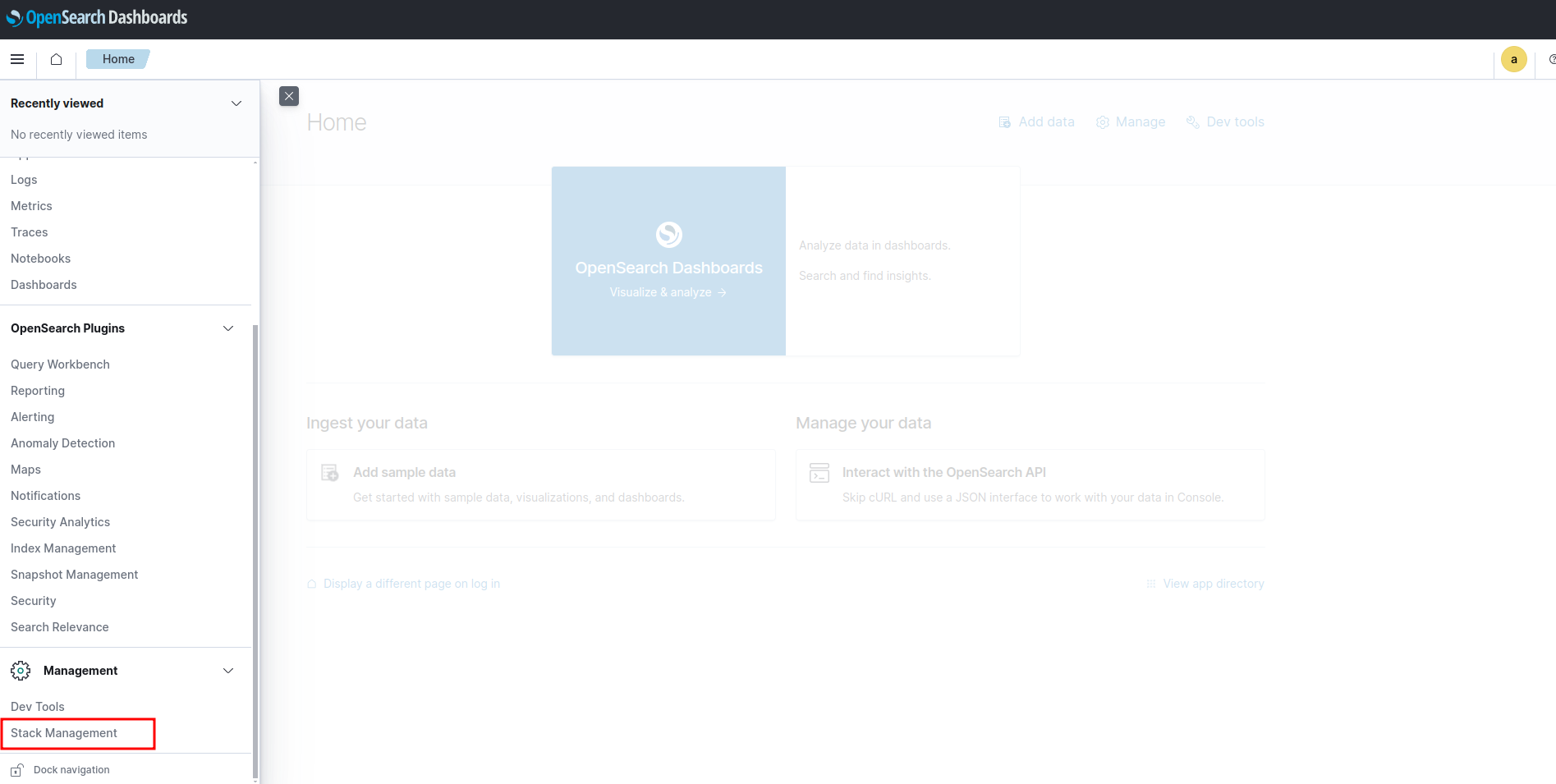
- เลือก index pattern แล้วเลือก Create index pattern
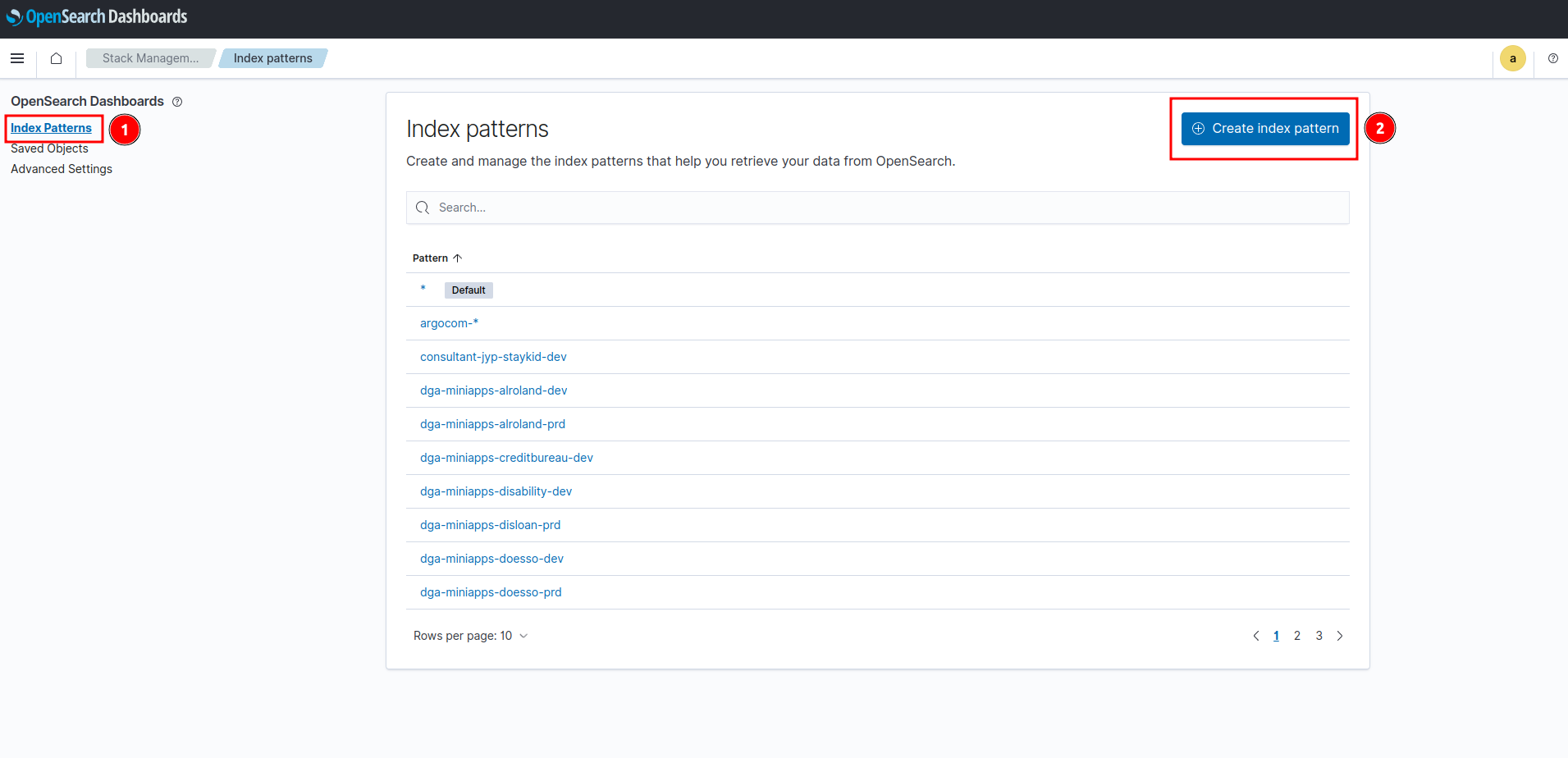
- กรอก index pattern ที่ต้องการโดย index pattern ที่กรอกต้อง match อย่างน้อยกับ 1 index
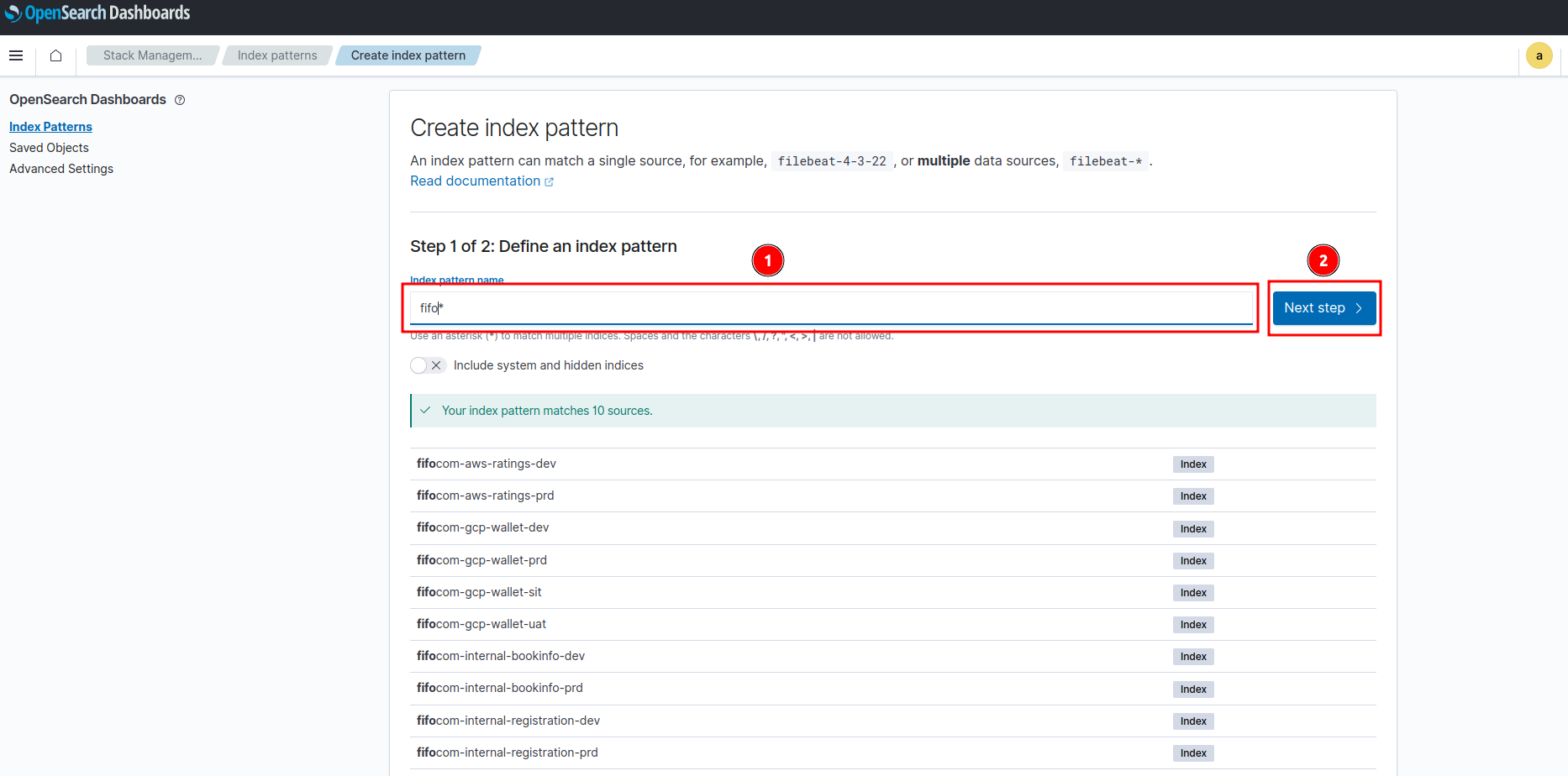
- เลือก primary time field จากนั้นกด Create index pattern
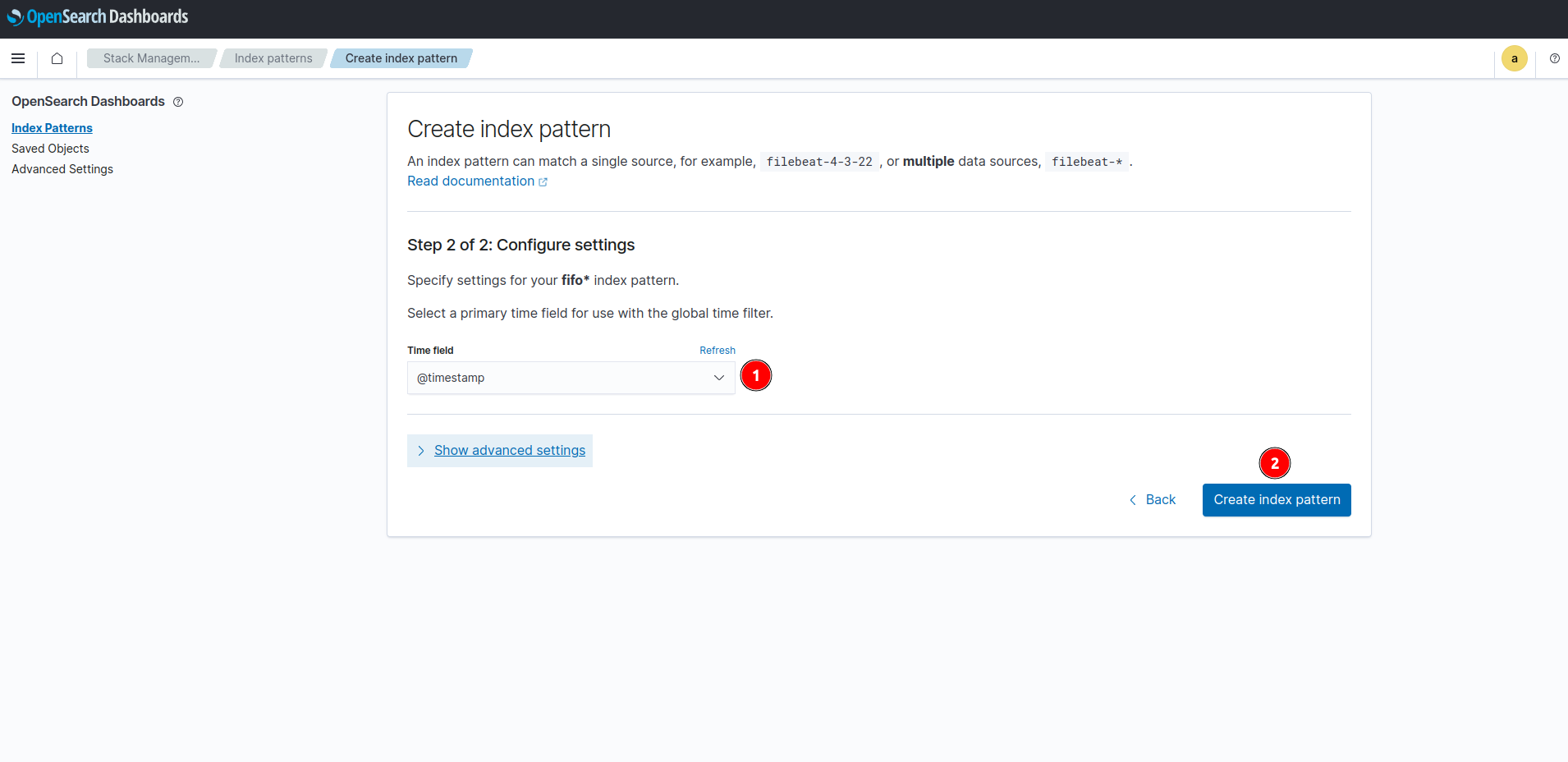
- รอสักครู่
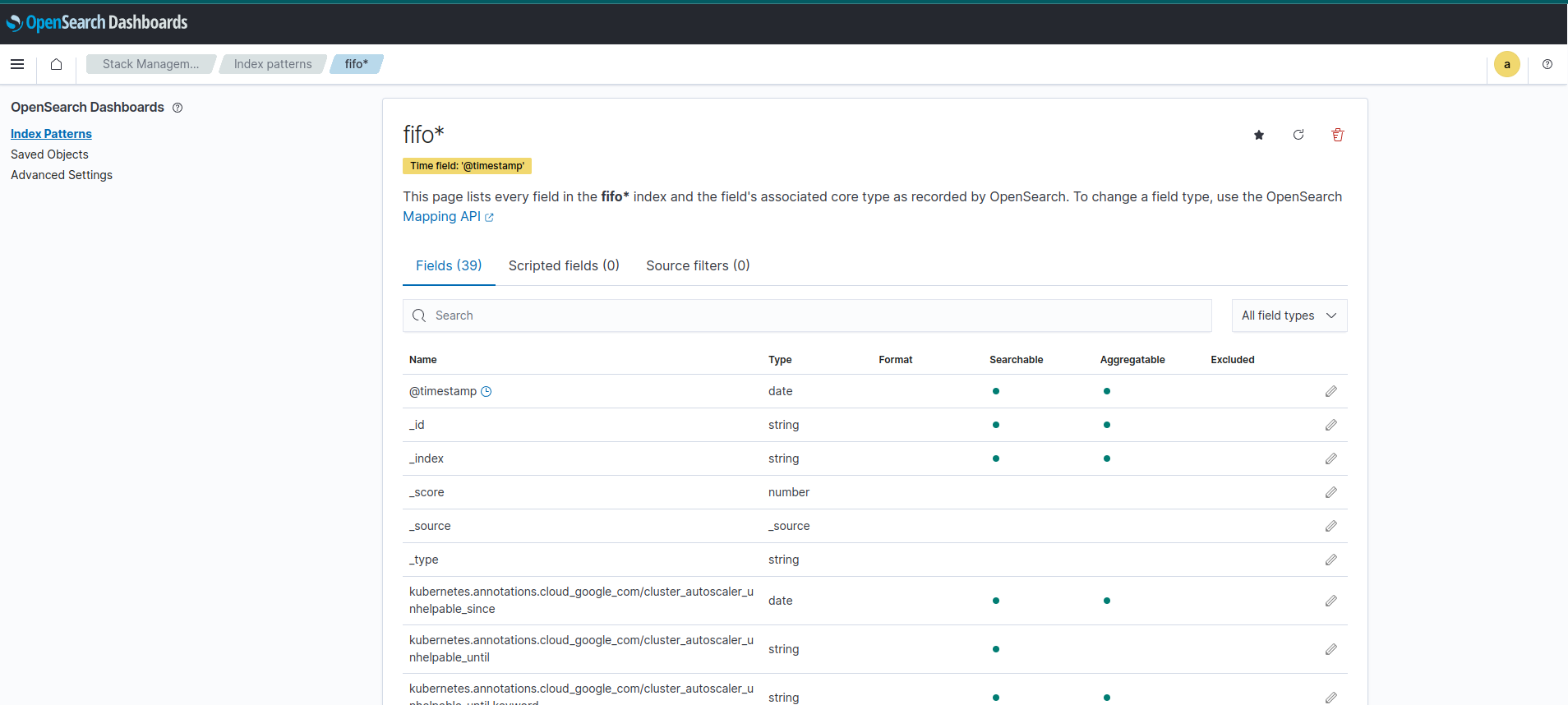
สร้าง Index pattern สำเร็จ
Opensearch Discover
จากหน้าแรกเปิดเมนูด้านซ้าน เลือก Discover
จากรูปจะอธิบายตามหมายเลข
- 1 ช่องพิม query โดยพิมพ์ ชื่อ field:ค่าที่ค้นหา opensearch จะกรองให้
- 2 เลือกช่วงเวลา เช่น 30 วันถึงปัจจุบัน
- 3 เพิ่ม field ที่จะกรองเพิ่ม
จากนั้นกด DQL จะแสดงผลลัพธ์ ดังรูป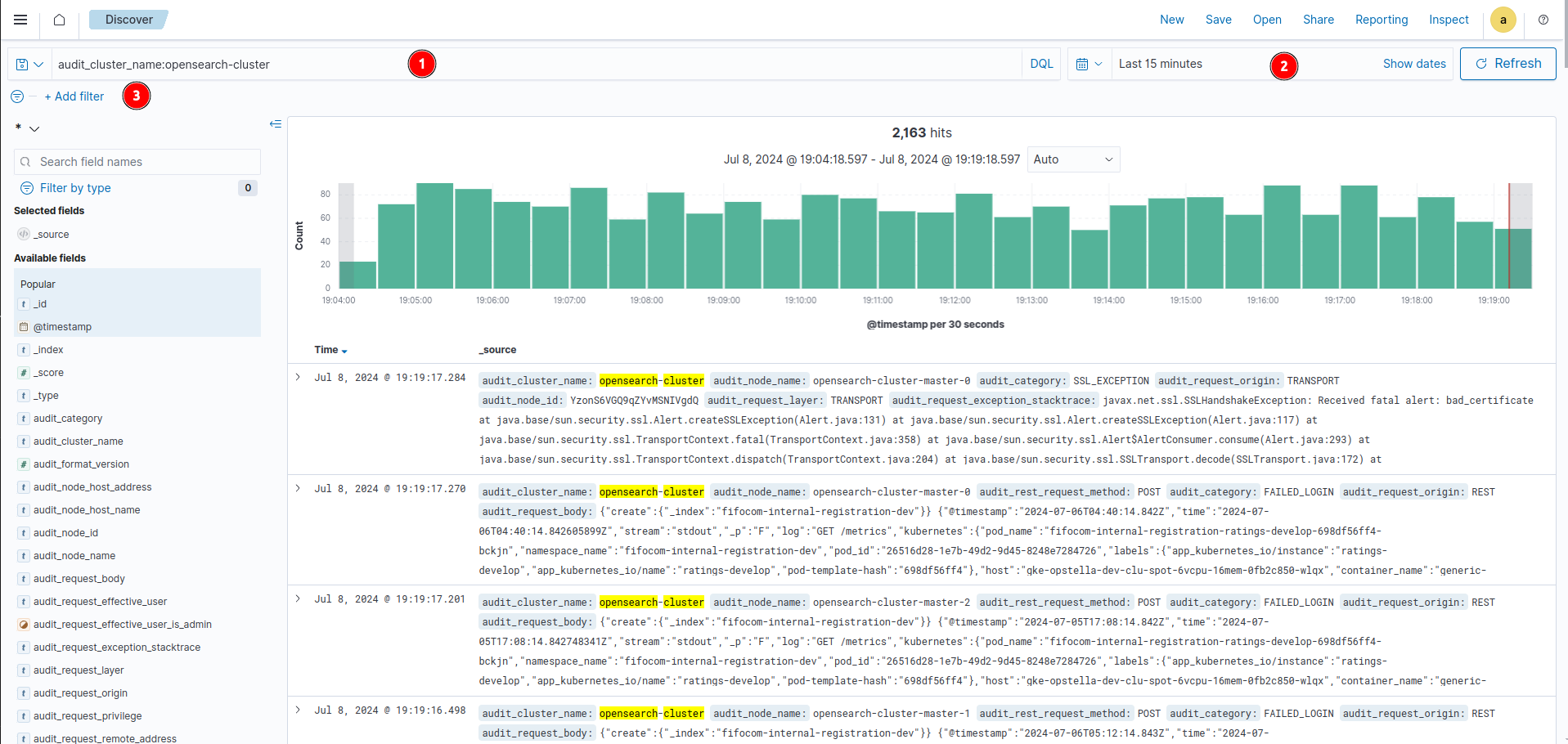
การสร้าง Dashboard
Dashboard ใน Opensearch คือนำข้อมูลที่กรองแล้วมาแสดงเป็น กราฟได้โดยสามารถปรับแต่งได้หลากหลายรูปแบบ โดยในหัวข้อจะยกตัวอย่างวิธีการสร้าง Dashboard เบื้องต้น
- หน้าแรกเปิดไปที่เมนูด้านซ้ายเลือก Dashboard
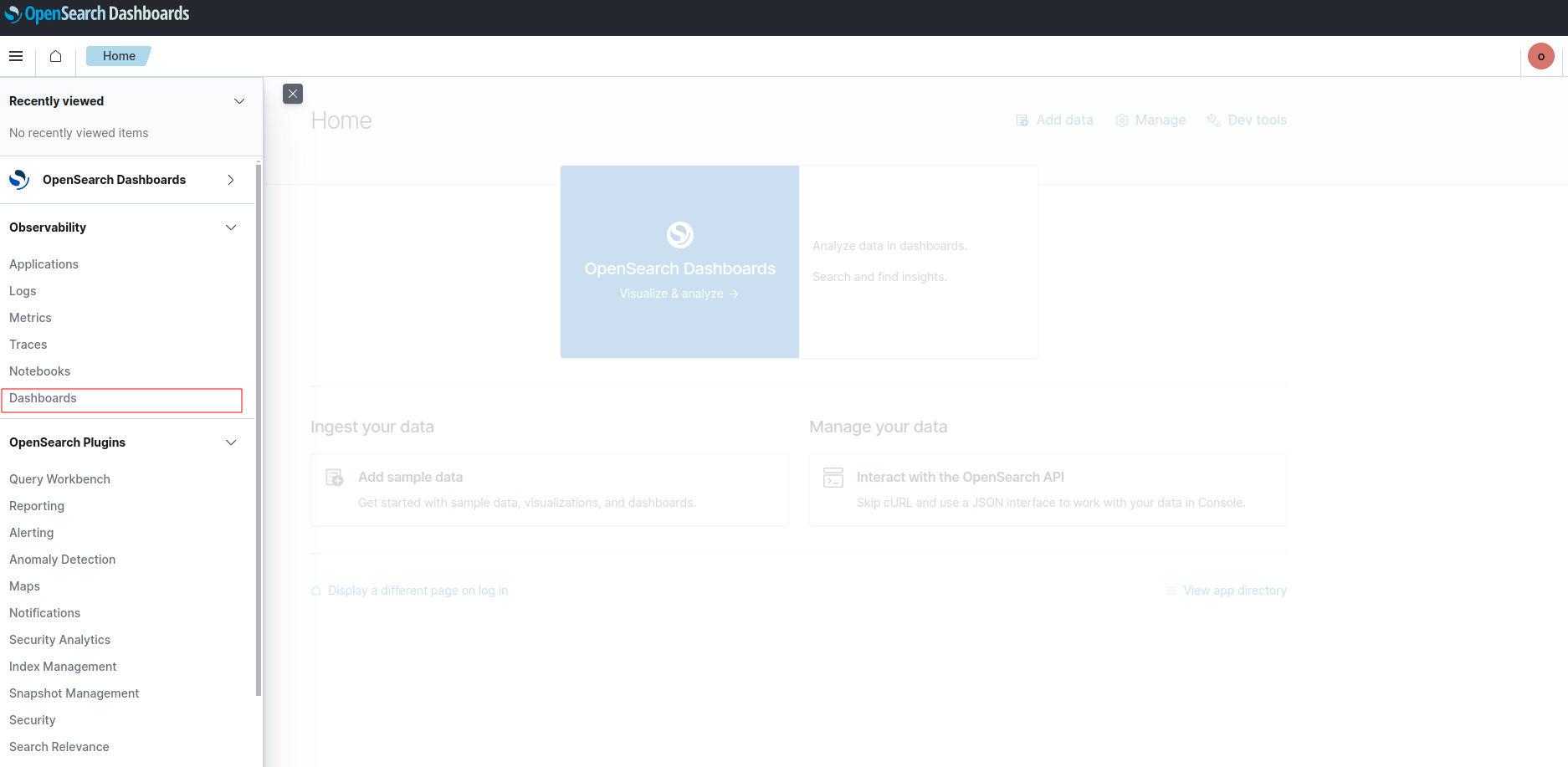
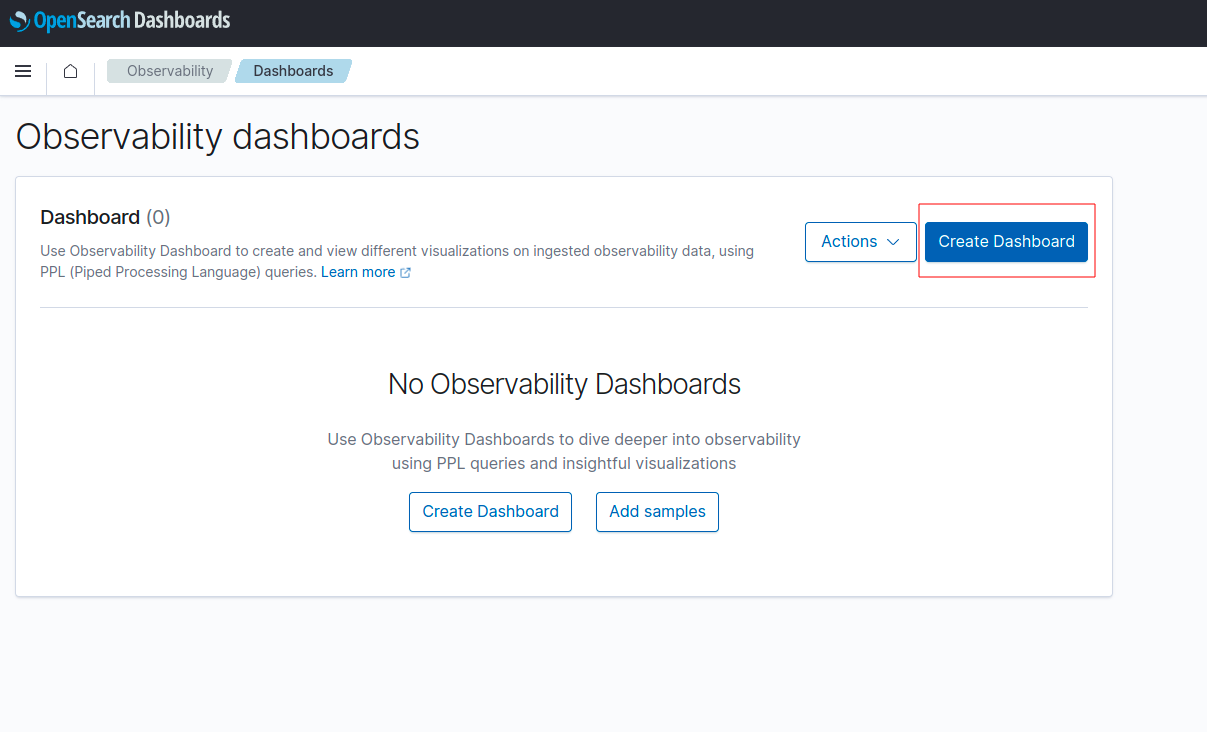
- เลือก Create Dashboard
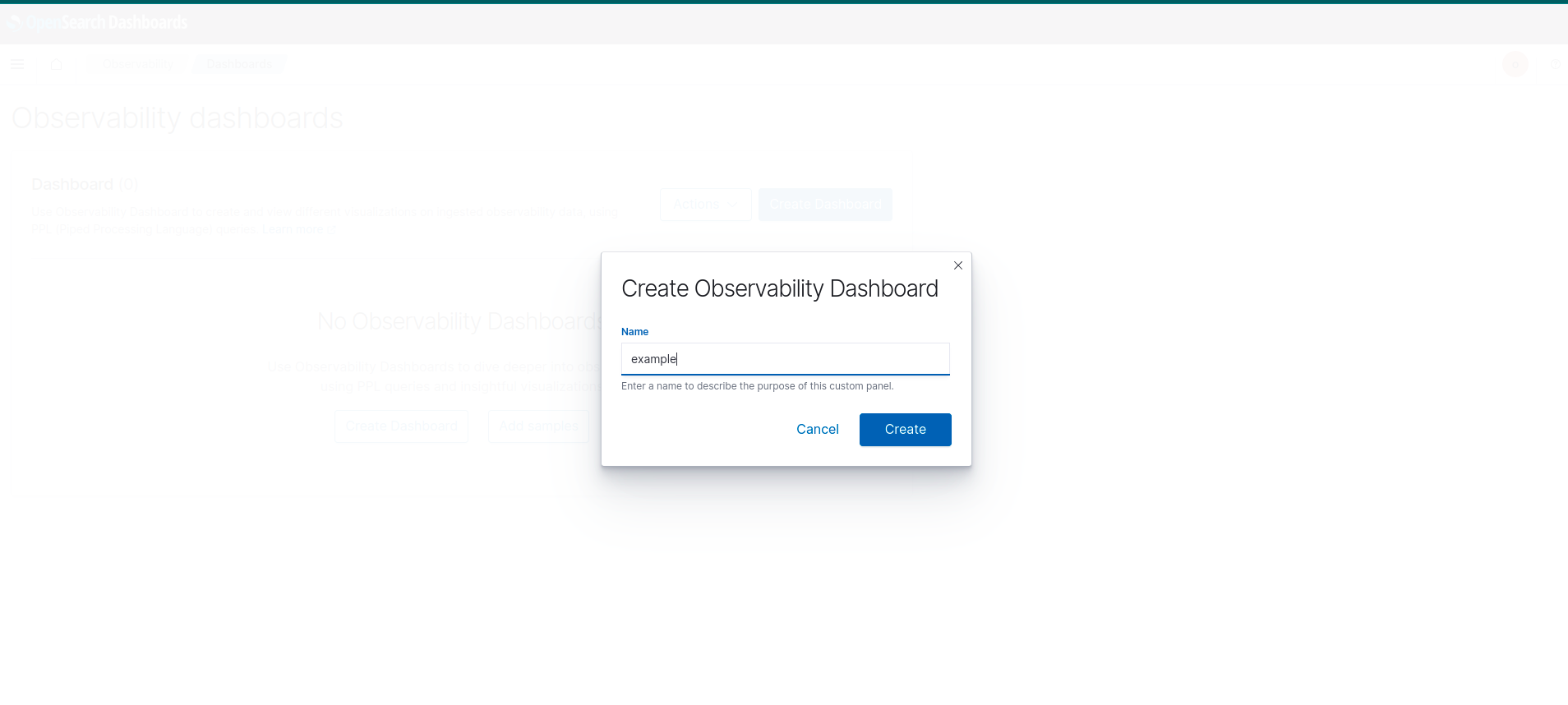
- ตั้งชื่อ Dashboard แล้วกด Create
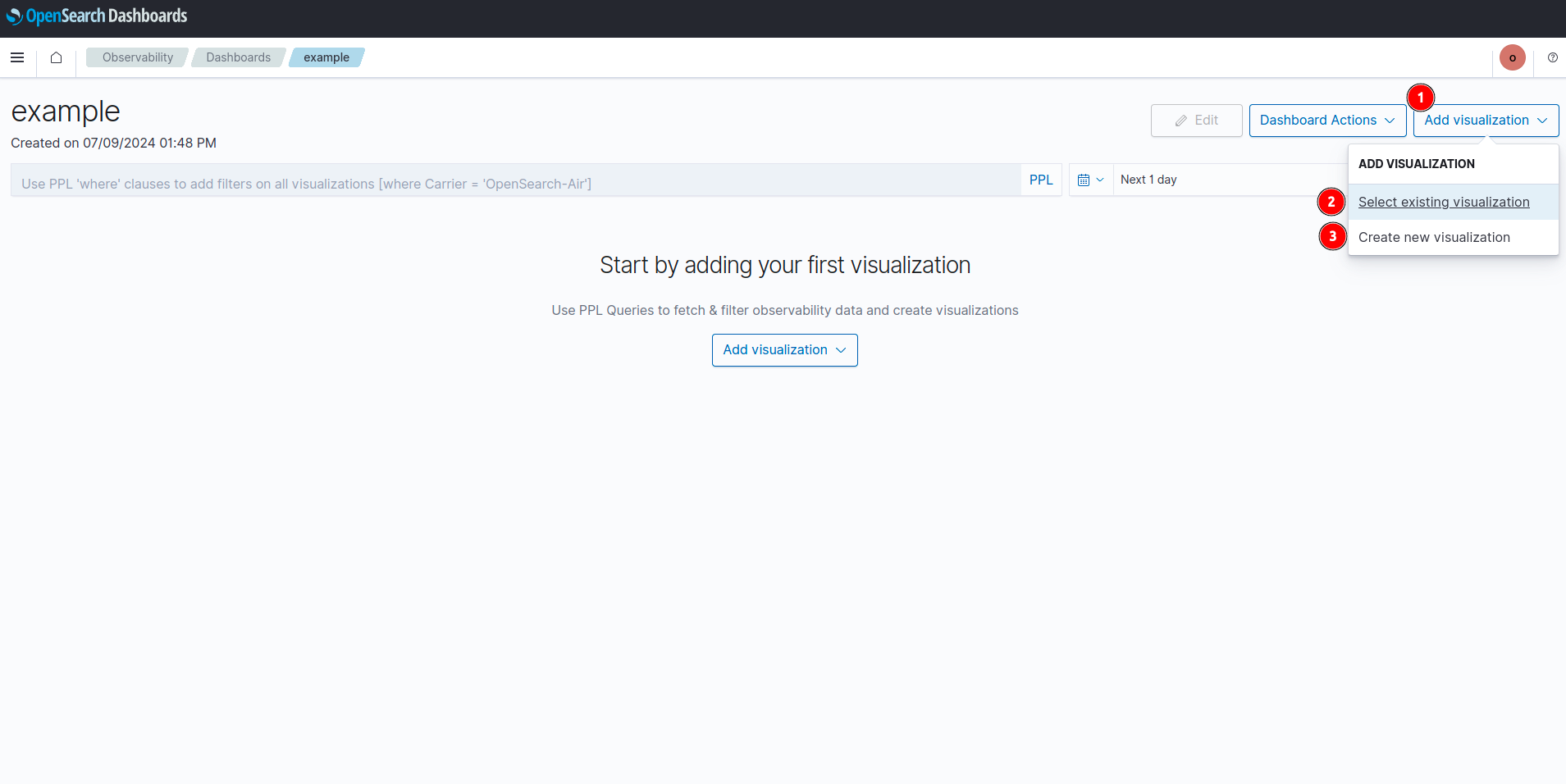
- กดปุ่ม Add Visualization จะมี 2 ตัวเลือก คือ
- Select existing Visualization เลือกกราฟที่มีอยู่แล้ว
- Create new Visualization สร้างกราฟใหม่ขึ้นมา
- เลือกสร้างใหม่จะปรากฏหน้าที่ให้กรอกว่าเลือกข้อมูลจาก index ไหน กำหนดเงื่อนแบบใด และช่วงเวลาที่ต้องการกรอง
- กดเลือกเมนู visaulize จะปรากฏ ดังรูป
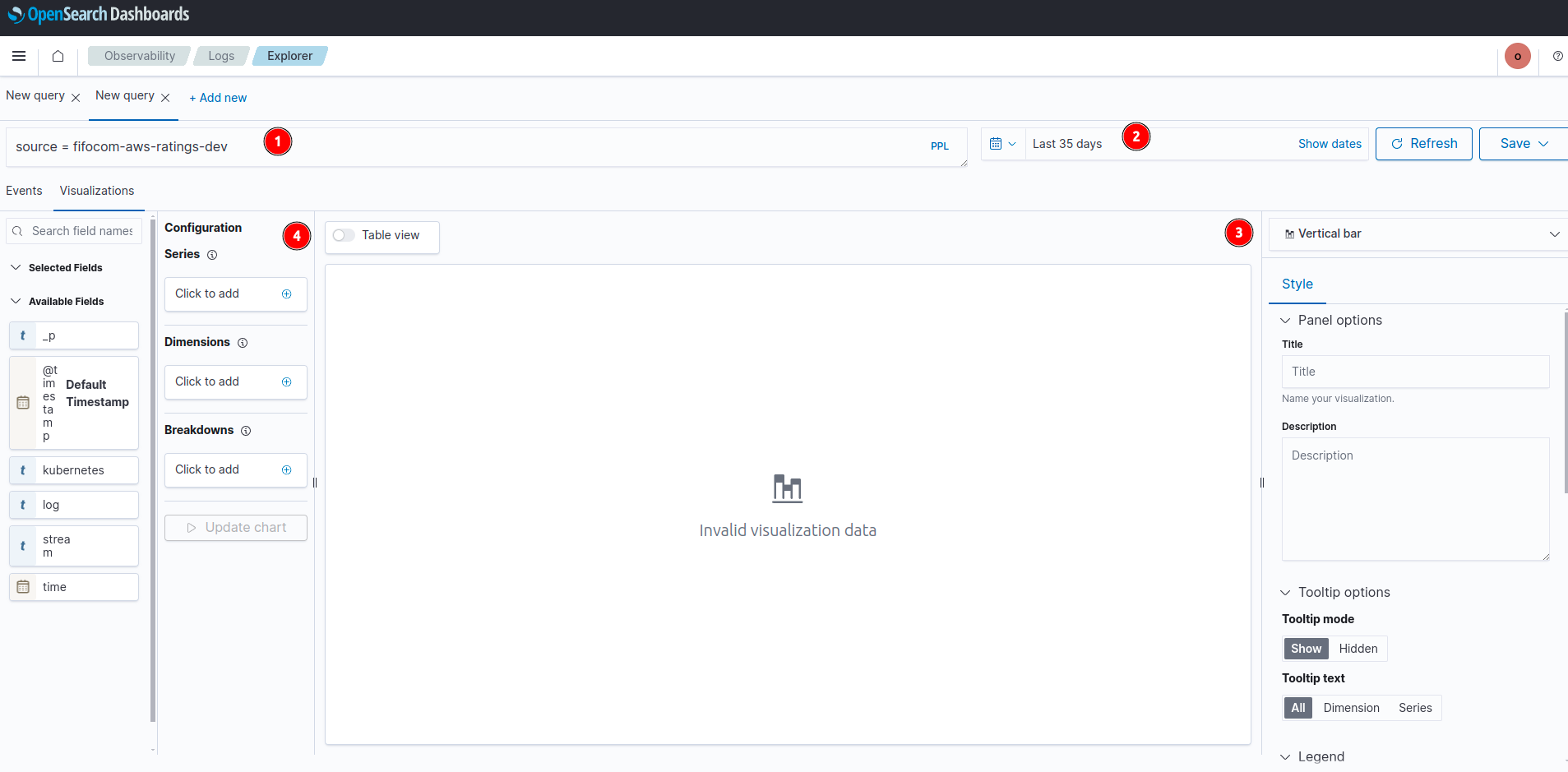
- ช่องกรอก query
- กรองช่วงเวลา
- เลือกประเภทกราฟ
- กำหนดองค์ประกอบของกราฟ
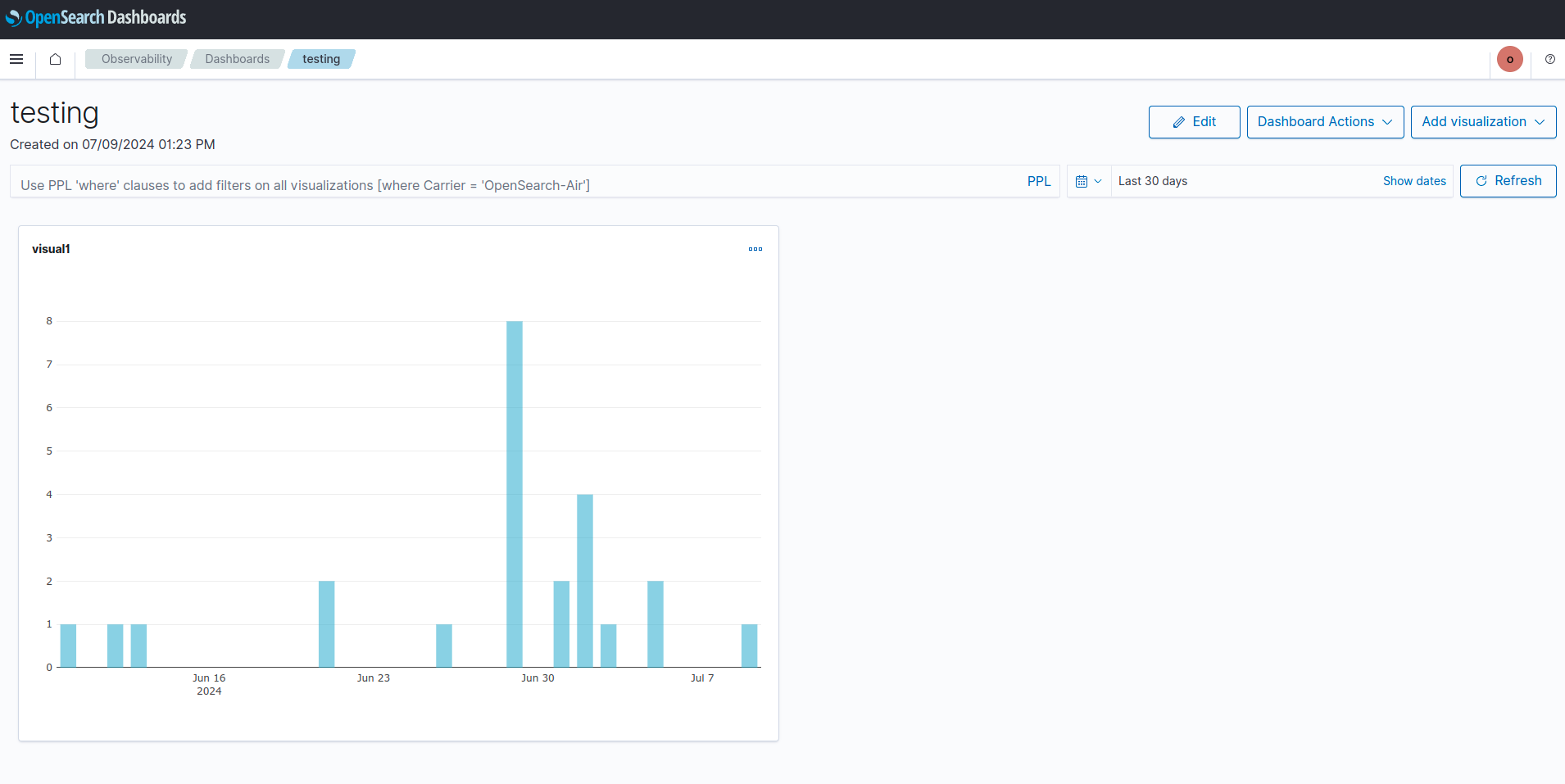
ยกตัวอย่างตามรูป
source=fifocom-aws-rating-devความหมายคือดึงข้อมูลจาก index ชื่อ fifocom-internal-bookinfo-dev, กำหนดช่วงเวลา 1 เดือนทื่แล้ว และ ใช้กราฟแบบ Vertical bar
ส่วนองค์ประกอบของกราฟจะมี series คือ กราฟแท่งให้ใช้ข้อมูลของ field ไหน ,แบ่งตามช่วงแบบไหน(ควรใช้เวลา หรือ field ที่เหมือนกัน)
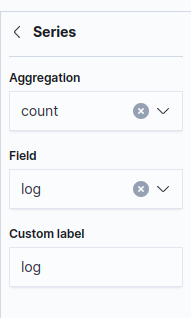
ลองกำหนดให้ series นับจำนวน log
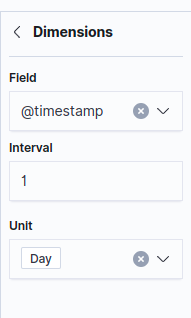
และ diemensions เป็น @timestamp ช่วง 1 วัน (ถ้า 1 เดือนจะแบ่งเป็น จำนวน log ในแต่ละวันของ 1 เดือนล่าสุด)
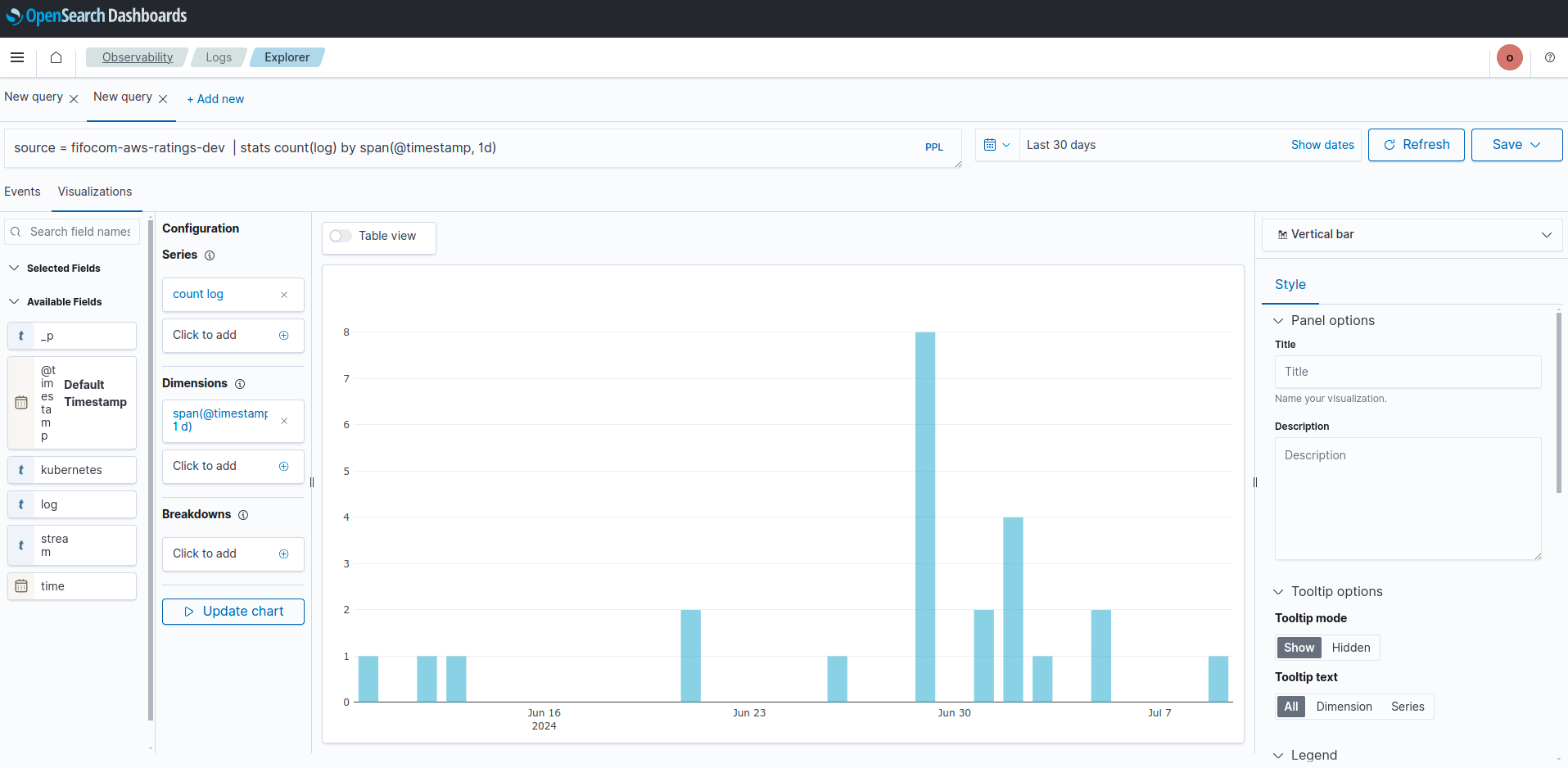
- กด update chart จะแสดงผล ดังรูป
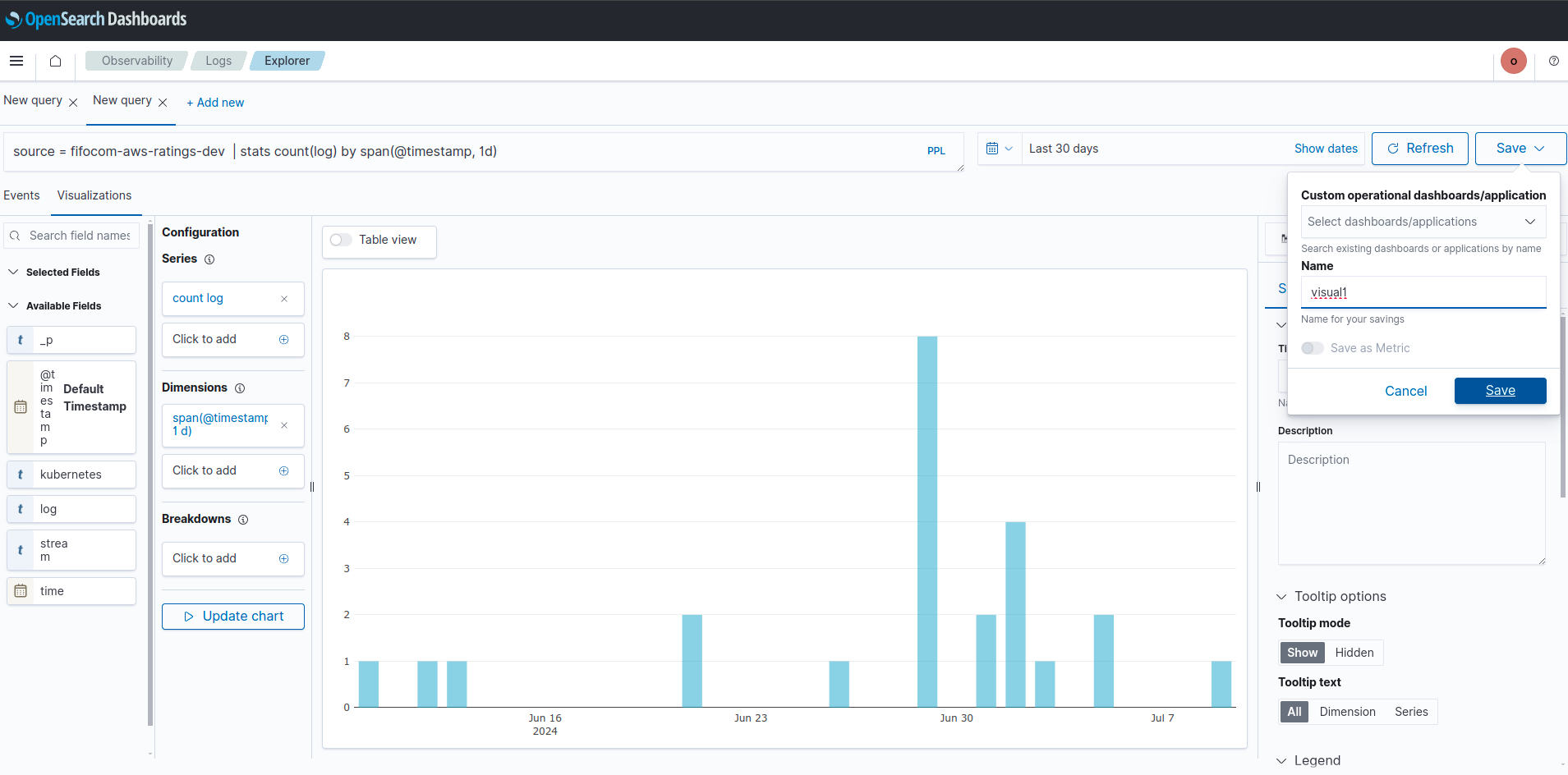
- ทำการกดบันทึกเพื่อนำไปใช้ต่อไป
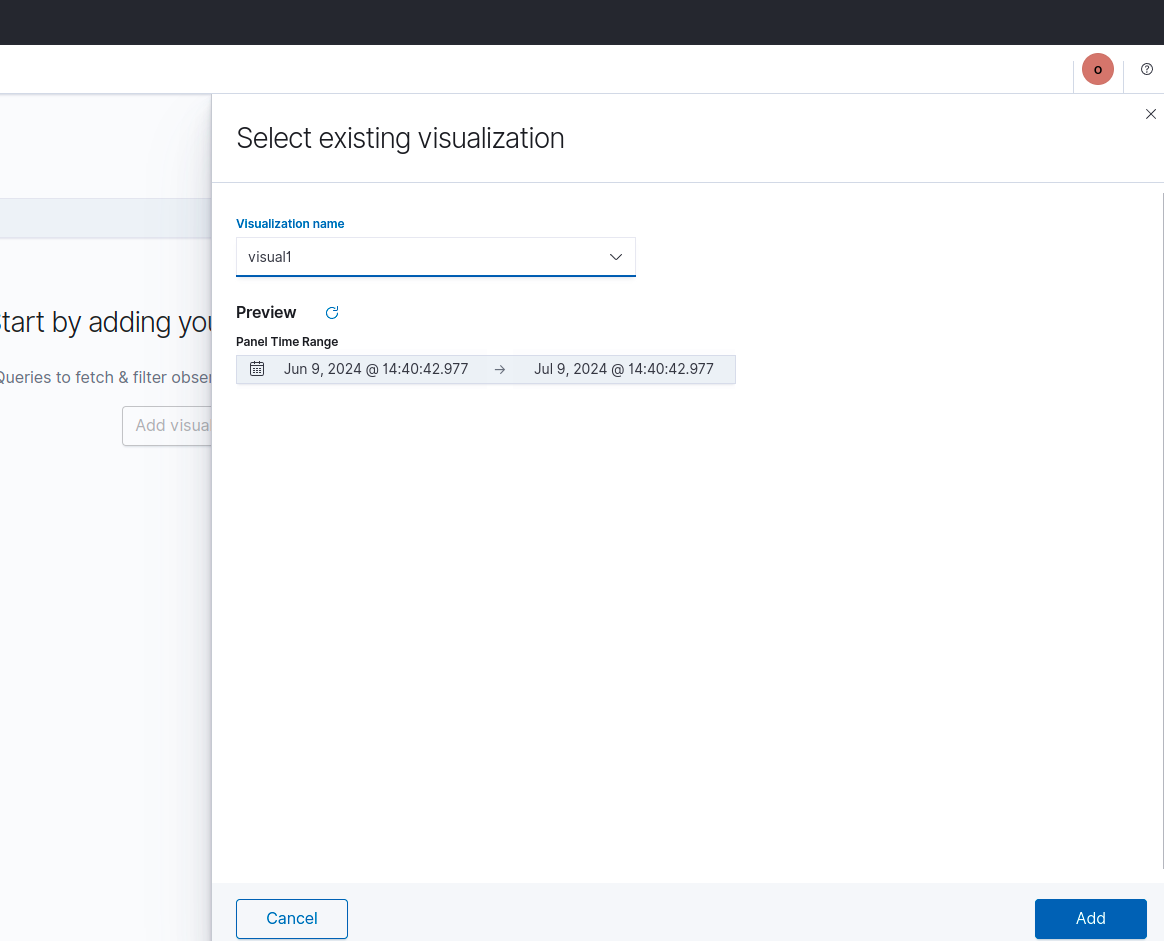
- กลับไปหน้าเลือกว่าจะใช้กราฟเดิม หรือสร้างใหม่ ให้เลือกกราฟที่มีอยู่จะเลือก กราฟที่สร้างขึ้น
- จะได้ผลลัพธ์ดังรูป นอกจากนี้ยังสามารถสร้างได้อีกหลายๆ กราฟมาใช้ภายใน Dashboard และปรับแต่งเพิ่มได้อีก
อ่านเพิ่มเติมได้ที่ Create Dashboars